- CodeCraft by Dr. Christine Lee
- Posts
- Discover the Magic of Named Entity Recognition (NER) with Python! 🧙♂️✨
Discover the Magic of Named Entity Recognition (NER) with Python! 🧙♂️✨
An NLP Project
Dr Christine Lee
18 Jun

Hello, explorers of the coding world! 🌟
Ready to uncover some magic in the realm of Natural Language Processing (NLP)?
Today, we’re diving into Named Entity Recognition (NER), a fascinating technique that helps computers understand and identify important elements in text. Whether it's recognizing names of people, places, or dates, NER can turn raw text into meaningful information.
Let’s jump in and see why NER is so cool and how you can use it with Python!
Why Learn Named Entity Recognition? 🤔
Imagine reading a news article and being able to instantly highlight all the names of people, places, organizations, and dates mentioned in it. That's exactly what NER does! Here are some practical applications:
News Aggregation: Automatically tag articles with relevant entities like celebrities, locations, or events.
Search Engines: Improve search results by understanding the context of queries.
Chatbots: Enhance user interaction by recognizing and responding to mentions of specific entities.
Data Analysis: Extract meaningful insights from large datasets by identifying key entities.
By learning NER, you'll be able to create smarter applications that understand text on a deeper level.
What Will You Learn? 📚
In this tutorial, you'll learn how to:
Understand what Named Entity Recognition (NER) is.
Set up the environment and import necessary libraries.
Apply NER to a sample text using Python and the
spaCylibrary.Visualise the identified entities.
Let’s Get Started! 🚀
1. What is Named Entity Recognition (NER)? 🕵️♀️
Named Entity Recognition (NER) is like having a superpower that allows you to spot and label the important pieces of information in any text. Imagine reading a sentence like: "Joe Biden was born on November 20, 1942, in Scranton, Pennsylvania." NER helps us identify and label " Joe Biden " as a PERSON, " November 20, 1942" as a DATE, and " Scranton, Pennsylvania" as a LOCATION.
Think of it like a highlighter that marks important words in different colors:
Person: Joe Biden
Date: November 20, 1942
Location: Scranton, Pennsylvania
2. Import Necessary Libraries 📚
We’ll use spaCy, a popular NLP library in Python, to perform NER.
import spacy
from spacy import displacy
# Load the pre-trained NLP model
nlp = spacy.load('en_core_web_sm')
Explanation
import spacy: Imports the SpaCy library.spacy.load('en_core_web_sm'): Loads a pre-trained NLP model for English. en_core_web_sm is a small model, but SpaCy also offers larger models with more features. "sm" stands for "small," meaning it's a compact and relatively lightweight version.
3. Apply NER to a Sample Text 📄
Let's analyse a sample text and see NER in action!
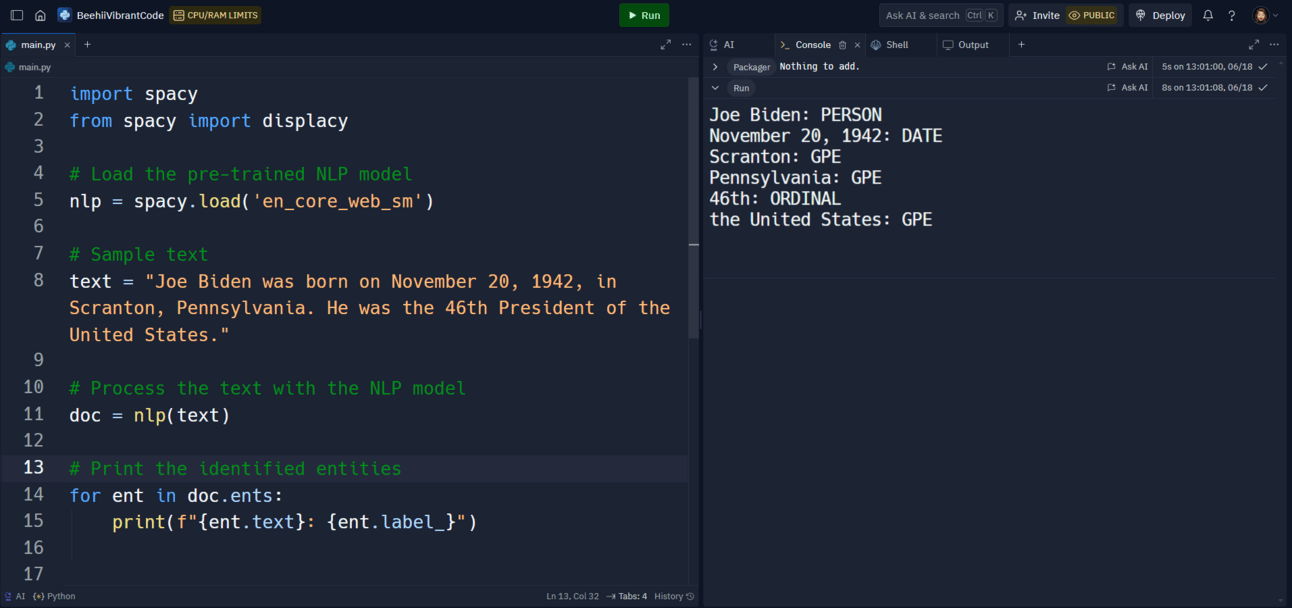
# Sample text
text = "Joe Biden was born on November 20, 1942, in Scranton, Pennsylvania. He was the 46th President of the United States."
# Process the text with the NLP model
doc = nlp(text)
# Print the identified entities
for ent in doc.ents:
print(f"{ent.text}: {ent.label_}")
Explanation
text: This is the input text string you want to process.nlp(text): This line passes the input text through SpaCy’s NLP pipeline, which includes various stages of text processing such as tokenization, part-of-speech tagging, named entity recognition, and more.
What Happens Under the Hood?
Here’s a detailed breakdown of what happens when doc = nlp(text) is executed:
Tokenization:
The text is split into individual tokens, which can be words, punctuation marks, numbers, etc. For example, the sentence "Hello, world!" is split into three tokens: "Hello", ",", and "world".
Part-of-Speech Tagging:
Each token is assigned a part-of-speech (POS) tag, indicating whether it is a noun, verb, adjective, etc. This helps in understanding the grammatical structure of the text.
Lemmatization:
Tokens are converted to their base forms (lemmas). For instance, "running" becomes "run". This helps in normalizing the text for further analysis.
Named Entity Recognition (NER):
Named entities like people, organizations, dates, and locations are identified and classified. For example, "New York" might be recognized as a "GPE" (Geopolitical Entity).
Dependency Parsing:
The syntactic structure of the sentence is analyzed, creating a dependency tree that shows relationships between tokens. This helps in understanding the sentence structure.
Vector Representation:
Each token is converted into a dense vector (word embedding) representing its semantic meaning. These vectors are useful for various downstream NLP tasks like text classification and similarity.
The Result:
docdocis a SpaCy Doc object containing the processed text. This object holds all the information extracted from the text, such as tokens, POS tags, named entities, and more.
Installation Notes
Before you could run the code to view the output, you need to install the en_core_web_sm model using the following command in your terminal (or the Shell terminal on Replit):
pip install -U spacy
python -m spacy download en_core_web_sm
Output
The program did a fantastic job of identifying key pieces of information:
Joe Biden: PERSON - The program recognized "Joe Biden" as a person's name.
November 20, 1942: DATE - It correctly identified that "November 20, 1942" is a date.
Scranton: GPE - The program figured out that "Scranton" is a geographical location.
Pennsylvania: GPE - It also recognized that "Pennsylvania" is a geographical location.
46th: ORDINAL - The program understood that "46th" is an ordinal number (like first, second, third, etc.).
the United States: GPE - It correctly identified "the United States" as a geographical location.
What is GPE?
"GPE" stands for Geopolitical Entity.
Think of it like this: when your computer program reads text, it's trying to figure out what kind of thing each word or phrase represents. A "Geopolitical Entity" is a fancy way of saying "a place on the map."
Geo: Means related to the Earth or geography.
Political: Means related to government or countries.
So, when your program identifies "Scranton" or "Pennsylvania" as "GPE," it's telling you that it recognizes those words as referring to specific locations that have political significance.
Output of NER
Here’s another simple example.
import spacy
# Load the small English model
nlp = spacy.load('en_core_web_sm')
# Text to be processed
text = "Apple is looking at buying U.K. startup for $1 billion."
# Process the text
doc = nlp(text)
# Accessing information from the doc object
for token in doc:
print(f"Token: {token.text}, POS: {token.pos_}, Lemma: {token.lemma_}")
for ent in doc.ents:
print(f"Entity: {ent.text}, Label: {ent.label_}")
Output
Token: Apple, POS: PROPN, Lemma: Apple
Token: is, POS: AUX, Lemma: be
Token: looking, POS: VERB, Lemma: look
Token: at, POS: ADP, Lemma: at
Token: buying, POS: VERB, Lemma: buy
Token: U.K., POS: PROPN, Lemma: U.K.
Token: startup, POS: NOUN, Lemma: startup
Token: for, POS: ADP, Lemma: for
Token: $, POS: SYM, Lemma: $
Token: 1, POS: NUM, Lemma: 1
Token: billion, POS: NUM, Lemma: billion
Token: ., POS: PUNCT, Lemma: .
Entity: Apple, Label: ORG
Entity: U.K., Label: GPE
Entity: $1 billion, Label: MONEY
Conclusion 🌟
Congratulations! You've just learned how to perform Named Entity Recognition (NER) using Python. With NER, you can transform raw text into structured data, making it easier to analyse and understand. This skill is incredibly powerful and opens up a world of possibilities for creating smarter and more intuitive applications.
Coding with a Smile 🤣 😂
The List of Lists: You start with a simple list, and then you need a list of lists. Soon, you have a list of lists of lists. It's like a Russian nesting doll of data structures. Unpacking them feels like unraveling a yarn ball that your cat has played with—fun, but potentially endless!
Recommended Resources 📚
What’s Next? 📅
In our next post, we'll dive into Sentiment Analysis, another exciting NLP technique that helps you determine the sentiment or emotion behind a piece of text. Imagine being able to analyse movie reviews, tweets, or customer feedback to understand how people feel. Stay tuned and keep exploring the magic of NLP! 🚀💖
Ready for More Python Fun? 📬
Subscribe to our newsletter now and get a free Python cheat sheet! 📑 Dive deeper into Python programming with more exciting projects and tutorials designed just for beginners.
Keep learning, keep coding 👩💻👨💻, and keep discovering new possibilities! 💻✨
Enjoy your journey into artificial intelligence, machine learning, data analytics, data science and more with Python!
Stay tuned for our next exciting project in the following edition!
Happy coding!🚀📊✨