- CodeCraft by Dr. Christine Lee
- Posts
- Why Polars is a Game-Changer for Data Analysts

Unleash the Power of Polars: The Secret Weapon for Data Scientists
Welcome back to another exciting edition of the CodeCraft newsletter! Today, we're diving into a powerful and lightning-fast DataFrame library in Python—Polars. If you've been using pandas, you'll find Polars to be a breath of fresh air with its speed and efficiency, especially for large datasets. Let’s get started!
|
What is Polars?
Polars is an in-memory DataFrame library for Rust and Python. It provides fast and efficient manipulation of structured data, similar to pandas but with several performance enhancements. Polars is designed to handle large datasets that might slow down pandas.
Why Polars?
Speed: Polars is designed to be fast, leveraging Rust's performance for heavy data processing tasks. Rust is one of the fastest growing programming languages in the world.
Memory Efficiency: Polars uses the Apache Arrow memory format, which is optimised for columnar data.
Parallel Execution: Polars can run operations in parallel, making it faster for large datasets.
Getting Started with Polars
Before we dive into the code, you’ll need to install Polars. You can do this via pip:
pip install polars
Real-Life Example: Analyzing Sales Data
Let's walk through a real-life example of how Polars can make your data analysis faster and more efficient. Imagine you have a large CSV file with sales data from an e-commerce store, and you want to analyse the monthly sales performance.
Structure of sales_data.csv
The sales_data.csv file contains sales transaction data from an e-commerce store. Here are the columns in this file:
transaction_id: A unique identifier for each transaction.
date: The date of the transaction (in
YYYY-MM-DDformat).customer_id: A unique identifier for each customer.
product_id: A unique identifier for each product.
quantity: The quantity of the product sold in the transaction.
price: The price of a single unit of the product.
sales: The total sales amount for the transaction (calculated as
quantity * price).
Sample Data
Here’s an example of how the data might look:
(To create the file, you can copy and paste the content into Notepad and save as sales_data.csv)
transaction_id,date,customer_id,product_id,quantity,price,sales
1,2024-01-15,101,5001,2,19.99,39.98
2,2024-01-17,102,5002,1,49.99,49.99
3,2024-02-05,103,5001,3,19.99,59.97
4,2024-02-18,101,5003,1,29.99,29.99
5,2024-03-03,104,5002,2,49.99,99.98
Explanation of Sample Data
transaction_id: 1, 2, 3, 4, 5
Unique identifiers for each transaction.
date: 2024-01-15, 2024-01-17, 2024-02-05, 2024-02-18, 2024-03-03
The dates on which these transactions occurred.
customer_id: 101, 102, 103, 101, 104
Unique identifiers for customers. Note that customer 101 made two purchases.
product_id: 5001, 5002, 5001, 5003, 5002
Unique identifiers for products. Note that product 5001 was purchased twice by different customers.
quantity: 2, 1, 3, 1, 2
The quantity of each product sold in the transactions.
price: 19.99, 49.99, 19.99, 29.99, 49.99
The price per unit of the product.
sales: 39.98, 49.99, 59.97, 29.99, 99.98
The total sales amount for each transaction, calculated as
quantity * price.
Using this structure and sample data, you can start experimenting with Polars to perform various data analyses.
Loading Data
First, let’s load the CSV file into a Polars DataFrame:
import polars as pl
# Load the CSV file
df = pl.read_csv("sales_data.csv")
print(df)
Output

Data Exploration
Now, let’s explore our data. We’ll look at the first few rows to get an idea of what our data looks like:
print(df.head(5))
Output

Basic Analysis
Let’s say we want to calculate the total sales for each month. Here’s how you can do it in Polars:
import polars as pl
# Load the CSV file
df = pl.read_csv("sales_data.csv")
# Convert the date column to a proper date type
df = df.with_columns(pl.col("date").str.strptime(pl.Date, "%Y-%m-%d"))
# Extract the month from the date
df = df.with_columns(pl.col("date").dt.month().alias("month"))
# Group by month and calculate total sales
monthly_sales = df.group_by("month").agg(pl.col("sales").sum().alias("total_sales"))
print(monthly_sales)
Output

Visualisation
To make our analysis more interesting, let's visualise the monthly sales using matplotlib:
import polars as pl
import pandas as pd
import matplotlib.pyplot as plt
# Load the CSV file
df = pl.read_csv("sales_data.csv")
# Convert the date column to a proper date type
df = df.with_columns(pl.col("date").str.strptime(pl.Date, "%Y-%m-%d"))
# Extract the month from the date
df = df.with_columns(pl.col("date").dt.month().alias("month"))
# Group by month and calculate total sales
monthly_sales = df.group_by("month").agg(pl.col("sales").sum().alias("total_sales"))
# Convert to pandas for plotting using a dictionary
monthly_sales_dict = monthly_sales.to_dict(as_series=False)
monthly_sales_pd = pd.DataFrame(monthly_sales_dict)
# Sort the DataFrame by the "month" column to ensure consistent plotting order
monthly_sales_pd = monthly_sales_pd.sort_values(by="month")
# Convert the month column to integer
monthly_sales_pd["month"] = monthly_sales_pd["month"].astype(int)
# Plot the data
plt.figure(figsize=(10, 6))
plt.plot(monthly_sales_pd["month"], monthly_sales_pd["total_sales"], marker='o')
plt.title("Monthly Sales Performance")
plt.xlabel("Month")
plt.ylabel("Total Sales")
plt.grid(True)
plt.show()
Output
Make sure to run the pip install pyarrow command in your environment to ensure pyarrow is installed.

Polars vs. Pandas
To give you a sense of how Polars stands out, let’s compare the performance of Polars with pandas on the same task:
import pandas as pd
import time
# Load the data using pandas
df_pandas = pd.read_csv("sales_data.csv")
# Convert the date column to datetime
df_pandas['date'] = pd.to_datetime(df_pandas['date'])
# Extract the month
df_pandas['month'] = df_pandas['date'].dt.month
# Group by month and calculate total sales
start_time = time.time()
monthly_sales_pandas = df_pandas.groupby('month')['sales'].sum().reset_index()
end_time = time.time()
print(f"Pandas Execution Time: {end_time - start_time:.4f} seconds")
Output
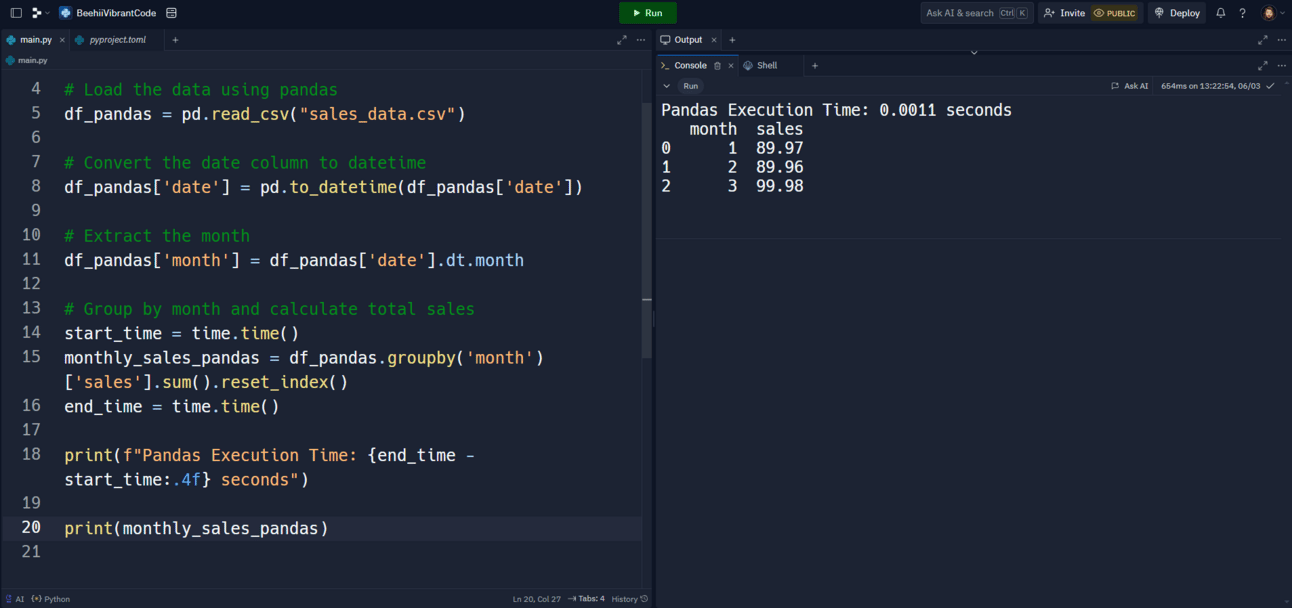
Using pandas: 0.0011 seconds
Compare this with the Polars execution time and you'll notice a significant speedup, especially with larger datasets.

Using polars: 0.0003 seconds
Fun with Polars
To keep things fun, let's create a small challenge. Using the same dataset, try to calculate the average sales per customer per month. Here’s a hint: you’ll need to use the .mean() function and group by both month and customer ID.
Conclusion
Polars is an excellent tool for anyone looking to speed up their data analysis tasks in Python. Its performance, combined with an easy-to-use syntax, makes it a great alternative to pandas, especially for large datasets.
|
Ready for More Python Fun? 📬
Subscribe to our newsletter now and get a free Python cheat sheet! 📑 Dive deeper into Python programming with more exciting projects and tutorials designed just for beginners.
Keep exploring, keep coding, and enjoy your journey into data analytics with Python!
Happy coding!🚀📊✨