- CodeCraft by Dr. Christine Lee
- Posts
- Python AI Training: Let the Fun Begin! 🎉
Python AI Training: Let the Fun Begin! 🎉
Dr Christine Lee
12 Oct

TL;DR
In this post, we’re diving into the practical steps for completing and running the machine learning code snippets we introduced earlier. 🎉
This will be your hands-on guide to turning those snippets into real, working models!
Ready to Train AI Models in Python?
Here’s the Easiest Way to Start! 💥
We’ll walk through the process of installing the necessary Python libraries, modifying the snippets to fit your needs, and running the code successfully.
By the end, you’ll be ready to create your own machine learning models. 👩💻✨
What You'll Learn
1. Installing Libraries🛠️
We’ll explain how to install the three key machine learning libraries we covered earlier: Scikit-learn, TensorFlow, and PyTorch.
With simple commands and a few clicks, you'll have everything set up in your Python environment.
2. Modifying Code Snippets📝
Learn how to customize the snippets to your specific use case.
Whether you're working with classification, regression, or clustering models, you’ll understand how to tweak parameters, adjust the dataset, and improve model performance.
3. Running the Code🏃♂️
We’ll provide step-by-step instructions for running the code in your development environment, ensuring that everything works smoothly, even if you’re new to machine learning.
Step 1: Installing the Libraries
Before you start working with machine learning, you need to install the right tools.
Here’s how to install the three must-know libraries:
Scikit-learn
Open your terminal or command prompt and run:
pip install scikit-learn
TensorFlow
For TensorFlow, you can run:
pip install tensorflow
PyTorch
For PyTorch, head to PyTorch's official site and follow the specific installation instructions for your operating system, or run:
pip install torch torchvision torchaudio
Once you have the libraries installed, you're ready to move on to coding!
Step 2: Modifying the Code Snippets
Here’s a quick refresher on the code snippets we shared earlier:
Scikit-learn: Great for basic ML models like classification and regression.
TensorFlow: Perfect for deep learning tasks.
PyTorch: Ideal for dynamic and flexible deep learning models.
You can adapt these snippets by simply changing the dataset or adjusting hyperparameters such as learning rates and the number of iterations.
This is your chance to play around and see how small changes can impact your model’s performance.
Step 3: Running the Code
Once you’ve made your modifications, you can run your code in PyCharm, Jupyter Notebook, or any other Python IDE.
For example, running a simple Scikit-learn model:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# Load dataset
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3)
# Train model
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Evaluate model
accuracy = model.score(X_test, y_test)
print(f"Accuracy: {accuracy}")
Simply copy-paste this into your editor and hit run!
You’ll be able to see your machine learning model in action. 🎉
Let's break down the code step-by-step:
1. Importing the Necessary Libraries:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
load_irisThis function loads the Iris dataset, a famous dataset in machine learning that contains 150 samples of iris flowers.
The dataset has four features (e.g., petal length, petal width), and the goal is to classify the species of the flower.
train_test_splitThis function splits your data into training and testing sets.
You use the training data to teach the model, and the testing data to evaluate how well the model learned.
RandomForestClassifierThis is a machine learning algorithm that fits multiple decision trees on various sub-samples of the data.
It combines their predictions to improve accuracy.
2. Loading the Iris Dataset:
data = load_iris()
This command loads the Iris dataset into the variable data.
The dataset contains both features (data.data) and target labels (data.target).
The features are the measurements of the iris flowers, and the target labels are the species.
3. Splitting the Data into Training and Testing Sets:
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3)
data.data: These are the features (measurements like petal length and width).data.target: These are the target labels (species of iris flower).
train_test_split: This function splits the data into:
X_train: Training set for the features.
X_test: Testing set for the features.
y_train: Training set for the labels.
y_test: Testing set for the labels.
test_size=0.3: This means 30% of the data will be used for testing, and 70% will be used for training.
4. Training the Model:
model = RandomForestClassifier()
model.fit(X_train, y_train)
RandomForestClassifier()Initializes a random forest classifier.
model.fit(X_train, y_train)This trains the model using the training data (`X_train` and
y_train).The model will learn the relationships between the features and the target labels.
5. Evaluating the Model:
accuracy = model.score(X_test, y_test)
model.score(X_test, y_test)
This evaluates the model by using the testing data (`X_test` and
y_test).It calculates how well the model predicts the species of iris flowers in the test set.
accuracy
The score (accuracy) represents the percentage of correct predictions made by the model.
It ranges from 0 (0% accuracy) to 1 (100% accuracy).
6. Printing the Accuracy:
print(f"Accuracy: {accuracy}")
This simply prints the accuracy of the model on the test data.
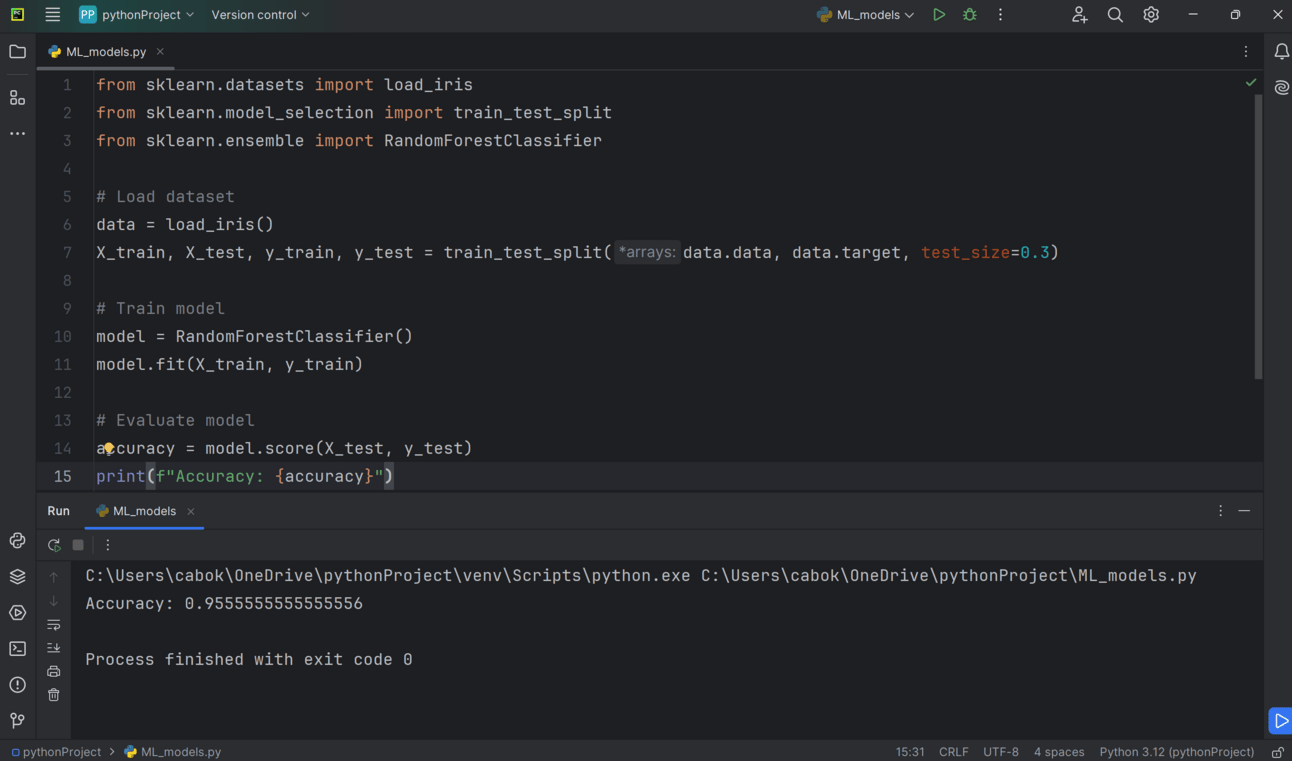
Accuracy of 95%
Example of What’s Happening
Imagine you’re teaching a robot to identify flowers based on their petal and sepal measurements.
You show it 70% of the flowers in your garden (training data), and it learns the patterns.
Then, you test its knowledge by giving it the remaining 30% of the flowers and asking it to identify them (test data).
Finally, you check how many flowers it got right, which gives you the accuracy score.
In this example, that’s what’s happening with the Iris dataset and the RandomForestClassifier.
Summary
By following these steps, you now know how to install the necessary libraries, modify the code snippets, and run your machine learning models!
Whether you're building something basic or diving into more complex tasks, these libraries are essential tools to have in your toolbox.
Final Thoughts
Machine learning can seem daunting at first, but breaking it down into manageable steps makes the process approachable for anyone.
With Scikit-learn, TensorFlow, and PyTorch at your disposal, the possibilities are endless.
🚀 Stay curious and keep experimenting—you’re well on your way to mastering machine learning!
Happy coding!🚀📊✨
Let’s Inspire Future AI Coders Together! ☕
I’m excited to continue sharing my passion for Python programming and AI with you all. If you’ve enjoyed the content and found it helpful, do consider supporting my work with a small gift. Just click the link below to make a difference – it’s quick, easy, and every bit helps and motivates me to keep creating awesome contents for you.
Thank you for being amazing!